如何免費打造自己的 Instagram Feed Widget(高度自定義!)
為什麼要自己做?
你是否遇過這些情況:
- 想在自己的網站嵌入 Instagram 動態,但官方 Embed 樣式醜又不能改
- 第三方服務(如 LightWidget、SnapWidget)免費版有水印、付費版又貴
- Instagram Graph API 申請流程繁瑣,還要過 App Review
- 想要完全掌控數據、樣式、緩存策略
這篇文章會帶你用 Cloudflare Workers + Apify + R2 + KV 打造一個 0 元成本(在免費額度內)、高度自定義、全自動更新 的 Instagram Feed Widget 後端 API。
前端怎麼渲染你隨意——React、Vue、原生 HTML 都行,因為我們會提供一個乾淨的 JSON API。
整體架構
先看一張圖了解資料流向:
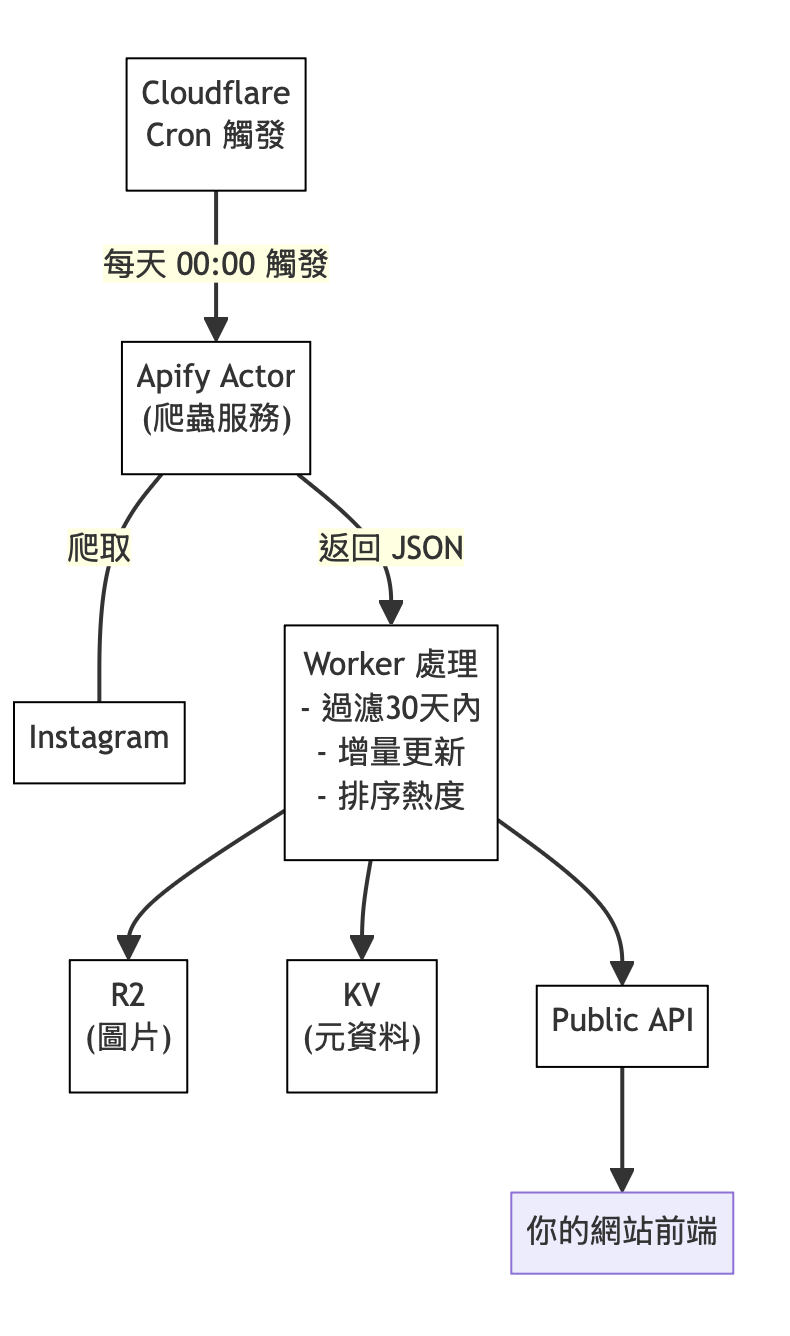
核心思路:把「爬取」和「對外服務」拆開。爬取一天只跑一次(省 Apify 額度),對外 API 直接讀 KV 快取(毫秒級回應,幾乎不耗 Worker 額度)。
不過這種方法不能即時反映 IG 新帖子和帖子變化(如likes、comments),但對於大多數展示用的 Feed Widget 來說,24 小時更新一次已經足夠了。
你會用到的服務(全部免費)
| 服務 | 用途 | 免費額度 |
|---|---|---|
| Cloudflare Workers | 跑後端邏輯 | 每天 10 萬次請求 |
| Cloudflare KV | 存帖子元資料 | 每天 10 萬次讀、1000 次寫 |
| Cloudflare R2 | 存圖片(避免 IG 連結過期) | 每月 10GB 儲存、無出站費用 |
| Apify | Instagram 爬蟲 | 每月 $5 美金額度(夠跑一個帳號一年) |
如果Widget 一天只自動更新一次的話,上面的額度是絕對用不完的。
第一步:準備 Apify 爬蟲
Apify 上有一個現成的 Instagram Scraper Actor,不用自己寫爬蟲。
- 到 apify.com 註冊帳號
- 搜尋並使用
apify/instagram-scraper - 在 Settings → Integrations → API tokens 拿到
APIFY_API_TOKEN - Actor ID 就是
apify~instagram-scraper(替換/為~)
爬蟲的呼叫參數長這樣:
const raw = JSON.stringify({ addParentData: false, directUrls: ['https://www.instagram.com/你的帳號/'], onlyPostsNewerThan: '30 days', // 只爬最近 30 天 resultsLimit: 1, resultsType: 'details', searchLimit: 1, searchType: 'user', });
重點是 onlyPostsNewerThan: '30 days'——只抓 30 天內的帖子,省額度也省 KV 空間。
第二步:為什麼要拆成兩個 Cron?
這是整個架構最關鍵的設計。看 scheduled 處理函式:
async scheduled(event: ScheduledEvent, env: Env, ctx: ExecutionContext) { if (event.cron === '0 0 * * *') { // 主任務: 每天 00:00 啟動 Apify 爬蟲 ctx.waitUntil(startApifyRun(env)); } else if (event.cron === '5 0 * * *') { // 檢查任務: 每天 00:05 檢查爬蟲結果 ctx.waitUntil(checkPendingRuns(env)); } }
為什麼不一次跑完? 因為 Apify 爬蟲是異步的——你發起請求後,它可能要跑 30 秒到 5 分鐘。Cloudflare Worker 的單次 CPU 時間有限制(免費版 10ms,付費版 30s),你不能一直 await 等它跑完。
解法:
- 00:00 發起爬蟲請求,拿到
runId,存進 KV - 00:05 根據
runId去 Apify 查狀態:如果SUCCEEDED,就抓資料;如果還在RUNNING,等下一輪
這樣每次 Worker 執行都很短,永遠不會超時。
啟動爬蟲後存狀態的關鍵代碼:
const runData: any = await response.json(); const runId = runData.data.id; await env.KV.put( 'apify_current_run', JSON.stringify({ runId: runId, status: 'RUNNING', startedAt: new Date().toISOString(), }) );
wrangler.toml 設定兩個 cron:
[triggers] crons = ["0 0 * * *", "5 0 * * *"]
第三步:增量更新的精妙之處
如果每次都重新處理所有帖子,那就要重複下載所有圖片到 R2——浪費頻寬、浪費時間。看這段增量更新邏輯:
// 獲取緩存的舊帖子 const cachedDataJson = await env.KV.get('instagram_posts_cache'); let cachedPosts: StoredPost[] = []; if (cachedDataJson) { const cachedData: CachedData = JSON.parse(cachedDataJson); cachedPosts = cachedData.posts || []; } // 處理API返回的帖子(增量更新) const processedApiPosts: StoredPost[] = await Promise.all( validPosts.map(async (post) => { // 查找緩存中的帖子 const cached = cachedPosts.find((p) => p.postId === post.id); let imageUrl = ''; // 如果緩存中有,則複用,否則上傳新圖片 if (cached) { imageUrl = cached.imageUrl; } else { imageUrl = await uploadImageToR2(post.displayUrl, post.id, env); } return { postId: post.id, caption: post.caption || '', // ... 其他欄位 likes: post.likesCount || 0, comments: post.commentsCount || 0, imageUrl, lastUpdated: now.toISOString(), }; }) );
核心邏輯:
- 帖子的
imageUrl(已上傳到 R2 的 CDN 連結)會在 cache 裡找有沒有 - 有的話直接複用,不重複下載
- 沒有的話(新帖子)才下載到 R2
但 likes 和 comments 每次都用 API 最新的值——這樣才能反映即時熱度。
第四步:處理「Apify 漏抓」的問題
這是一個很容易踩的坑。Apify 的這個爬蟲最多只能回傳最近的 12 則帖子,但你想顯示 30 天內全部的帖子。如果 30 天內你發的帖子超過 12 則,舊帖子便會從 API 返回中消失。
解法是把「API 這次回來的」+「以前抓過但這次沒回來、還沒滿 30 天的」合併起來,這樣就不會漏掉舊帖子了(缺點是舊帖子的likes 和 comments不會被更新。但是考慮到舊帖子的互動一般比新帖子少得多,如果不介意數據稍不準確的話,只是想要展示一下帖子的話還是能接受的)。
// 創建 postId 的 Set 用於快速查找 const apiPostIds = new Set(processedApiPosts.map((p) => p.postId)); // 從緩存中獲取不在 API 返回中的帖子(30天內的) const cachedOnlyPosts = cachedPosts.filter((post) => { if (apiPostIds.has(post.postId)) return false; // 已在 API 中返回 const postDate = new Date(post.date); return postDate >= thirtyDaysAgo; // 仍在30天內 }); // 合並所有帖子: API返回的 + 緩存中的(不重覆) const allProcessedPosts = [...processedApiPosts, ...cachedOnlyPosts];
效果:合併「API 這次回來的」+「以前抓過但這次沒回來、還沒滿 30 天的」。同時 30 天前的帖子自動被丟棄(因為 cache 篩選時就過濾掉了),KV 不會無限膨脹。
第五步:產出前端要的兩種列表
通常 Feed Widget 會想展示「最熱門」和「最新」兩種視圖:
// 獲取最熱門的3個帖子 const topPosts = [...allProcessedPosts] .sort((a, b) => b.likes - a.likes) .slice(0, 3); // 獲取最新的6個帖子 const latestPosts = [...allProcessedPosts] .sort((a, b) => new Date(b.date).getTime() - new Date(a.date).getTime()) .slice(0, 6);
數量可以隨意調整。最後一起塞進 KV:
await env.KV.put( 'instagram_posts', JSON.stringify({ profile, topPosts, latestPosts, }) );
第六步:圖片為什麼要存到 R2?
Instagram 返回的圖片 URL 大概長這樣:
https://scontent-xxx.cdninstagram.com/v/t51.2885-15/xxx.jpg?_nc_ht=...&oh=...&oe=68XXXXXX
注意那個 oe= 參數——那是 expiry timestamp。這些 URL 大約只活 24-48 小時就失效。你不能直接把它們塞給前端,否則 widget 隔天就全裂圖。
解法:下載到自己的 R2,配個自訂域名(如 cdn.jackycheung.dev):
async function uploadImageToR2(imageUrl: string, postId: string, env: Env): Promise<string> { const fileName = `${postId}.jpg`; // 檢查文件是否已存在 const existingObject = await env.R2_BUCKET.head(fileName); if (existingObject) { return `https://cdn.jackycheung.dev/${fileName}`; } // 文件不存在,下載並上傳 const imageResponse = await fetch(imageUrl); const imageBuffer = await imageResponse.arrayBuffer(); const contentType = imageResponse.headers.get('content-type') || 'image/jpeg'; await env.R2_BUCKET.put(fileName, imageBuffer, { httpMetadata: { contentType }, }); return `https://cdn.jackycheung.dev/${fileName}`; }
R2 的好處:
- 零出站費用:用戶從 R2 下載圖片不收你的錢(這在 AWS S3 上會貴死你)
- 自訂域名:直接綁定
cdn.你的域名.com - 永久有效:圖片只要不刪就一直在
R2 設定步驟:
- Cloudflare Dashboard → R2 → Create bucket
- Settings → Public access → 啟用 Custom Domain
- 綁定
cdn.yourdomain.com
第七步:對外 API 設計
對外只開一個 /api/posts 端點,從 KV 直接讀:
async function handleGetPosts(env: Env): Promise<Response> { const cached = await env.KV.get('instagram_posts'); if (!cached) { return new Response( JSON.stringify({ error: 'No data available yet. Please wait for scheduled task to complete.', }), { status: 404, headers: { 'Content-Type': 'application/json', 'Access-Control-Allow-Origin': '*' } } ); } return new Response(cached, { headers: { 'Content-Type': 'application/json', 'Access-Control-Allow-Origin': '*', // 允許前端跨域呼叫 }, }); }
重點:
Access-Control-Allow-Origin: *必須加,否則前端網站無法跨域呼叫- 直接把 KV 裡的 string 回傳(不用
JSON.parse再stringify),省 CPU 時間 - 沒 cache 就回 404,避免在沒資料時讓前端誤判
第八步:手動觸發端點(除錯用)
排程任務的問題是「你不知道它什麼時候跑、跑了沒」。所以加兩個手動觸發端點:
// 手動觸發啟動爬蟲 if (url.pathname === '/api/trigger-start') { return handleTriggerStart(request, env); } // 手動觸發檢查狀態 if (url.pathname === '/api/trigger-check') { return handleTriggerCheck(request, env); }
這兩個必須加 token 驗證,否則任何人都能消耗你的 Apify 額度:
function verifyToken(request: Request): boolean { const url = new URL(request.url); const token = url.searchParams.get('token'); return token === 'jackycheung_instagram'; }
改進建議:上面的 token 是硬編碼的,正式使用請改成從
env.API_TOKEN讀取(Worker secret),不要 commit 到 git。
使用方式:
curl "https://your-worker.workers.dev/api/trigger-start?token=xxx"
curl "https://your-worker.workers.dev/api/trigger-check?token=xxx"
部署後可以先手動跑一次,不用等到午夜。
第九步:前端怎麼用
前端只要 fetch 一次 API:
const res = await fetch('https://your-worker.workers.dev/api/posts'); const { profile, topPosts, latestPosts } = await res.json(); // profile: { username, fullName, biography, profilePicUrl, followersCount, postsCount } // topPosts: [{ postId, caption, hashtags, date, url, likes, comments, imageUrl }, ...] // latestPosts: 同上
樣式完全你自己決定。一個極簡的 vanilla JS 範例:
<div id="ig-feed"></div> <script> fetch('https://your-worker.workers.dev/api/posts') .then(r => r.json()) .then(({ latestPosts }) => { document.getElementById('ig-feed').innerHTML = latestPosts.map(p => ` <a href="${p.url}" target="_blank"> <img src="${p.imageUrl}" alt="${p.caption.slice(0, 50)}" /> <div>❤️ ${p.likes} · 💬 ${p.comments}</div> </a> `).join(''); }); </script>
進階版可以做成:
- 瀑布流 / 九宮格 / 輪播
- 點擊放大顯示 caption
- 切換「最熱」「最新」tab
- 顯示 followers 數字動畫
- 按 hashtag 過濾
因為你拿到的是純 JSON,想怎麼玩都行。