用Qwen3-VL + Cloudflare D1 + Worker實作基於AI OCR的全文搜索工具
近來心血來潮突然想做一個能搜索某漫畫全本文字的工具app,於是想幹就幹,馬上就著手做了。
一開始我搜索的是現有的OCR工具,例如百度開源的PaddleOCR,但一般的OCR工具用於識別結構複雜的漫畫圖片和豎行文字(我用的是中文譯本)相當不友好。
就在這時候我發現阿里的Qwen3-VL-flash 多模態模型能識別複雜圖片、OCR的精度很高,更能讀懂人類指令、識別圖片的特定元素,輸出結構化資料。最重要是價格便宜,系統也會贈送新會員100萬token使用。於是試了一下,正是我要找的東西!
我找了接近8000張漫畫圖片,總大小2GB以上。我全程用Claude 4.5寫了段Python代碼,把8000張漫畫傳到阿里平台來讓AI識別。最終的結果很不錯(雖然還是有一些錯字)。最終輸入了1700多萬token,這樣大量的輸入(輸出只有60萬token,跟輸入相比不值一提了),總成本只有1美元多一點!
雖然最重要的數據拿到了,但實作全文搜索才是重頭戲。我快速用vite+react搭了個前端架子(基本上也是Claude 4.5完成)
後端我選的是免費的Worker和Cloudflare D1。Worker屬於Serverless架構,特別適合我這種純前端快速開發。而Cloudflare D1是基於SQLite的關係型數據庫,而其作為Cloudflare套裝的一部分,容許用戶輕鬆、接近零配置地連結worker,非常方便。
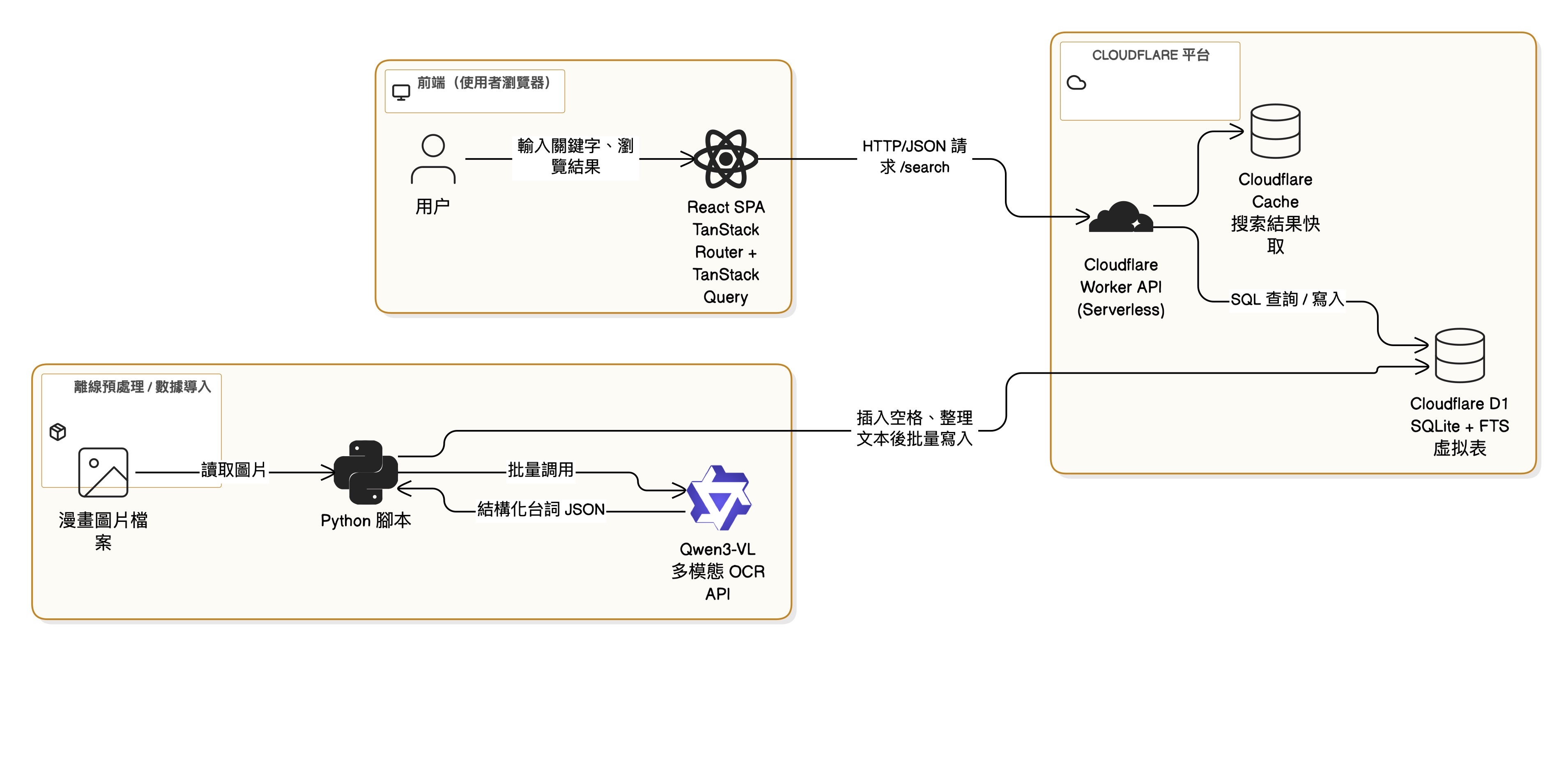
我用了一頁文字一行的方式來把數據灌入數據庫。在我想要搜索數據庫文字是,很容易便想到用Like語句來搜尋哪些頁數有特定文字出現。
但是,我發現Cloudflare D1的計費是根據SQL掃描行數來計算的。如果是這樣做的話,每一次搜索都要掃描全部8000多行!而Cloudflare D1免費方案只容許每日500萬行,這樣的話一天只能搜500多次。如果我要開放使用的話,這個數字無疑少得可憐,近乎不可用。
於是我搜了一下,發現SQLite提供了FTS虛擬表的技術,專門用於全文搜索,能高效地查詢包含一個或多個搜尋詞的大量資料。
但是用了FTS後,卻發現幾乎搜不到東西!又經過一番調查後,發現FTS虛擬表是基於文本中的單詞、短語或關鍵字進行索引或分詞,來實現高效搜索。而它預設的分詞器是不支持中文的(因為它用空格和標點來分詞)。雖然有人開發了供中文使用的分詞器,但D1很明顯並不支持自定義分詞器,難道只能硬著頭皮用Like來搜索了嗎?
我仔細想了一下,既然它用空格和標點來分詞,那是不是可以用一個程序把所有中文字符之間插入一個空格,再導入到FTS表呢?
於是我嘗試用了這種方法,果然能搜到東西了!掃描行數也確實因此大大降低,一般搜索,由低頻詞到高頻詞,可能也就幾十行到幾百行。
當然,掃描行數還是能降則降,畢竟這是算錢的。我又用了Cloudflare Cache來把搜尋結果緩存起來,以減少調用數據庫。
然而,另一個問題出現了,那就是前端分頁功能。
分頁功能我們很容易便想到用limit 和offset來實現,但是原來如果用戶搜索時搜到極高頻詞,跳到比較後的頁數時,數據庫需要由頭掃描到那個位置的那行,消耗的掃描行數不少。
於是這裡採用了游標分頁的方式,前端需要傳回上次搜索結果分頁的最後一個item的id,傳到後端讓數據庫從那個地方開始掃描,便能節省不少掃描行數。
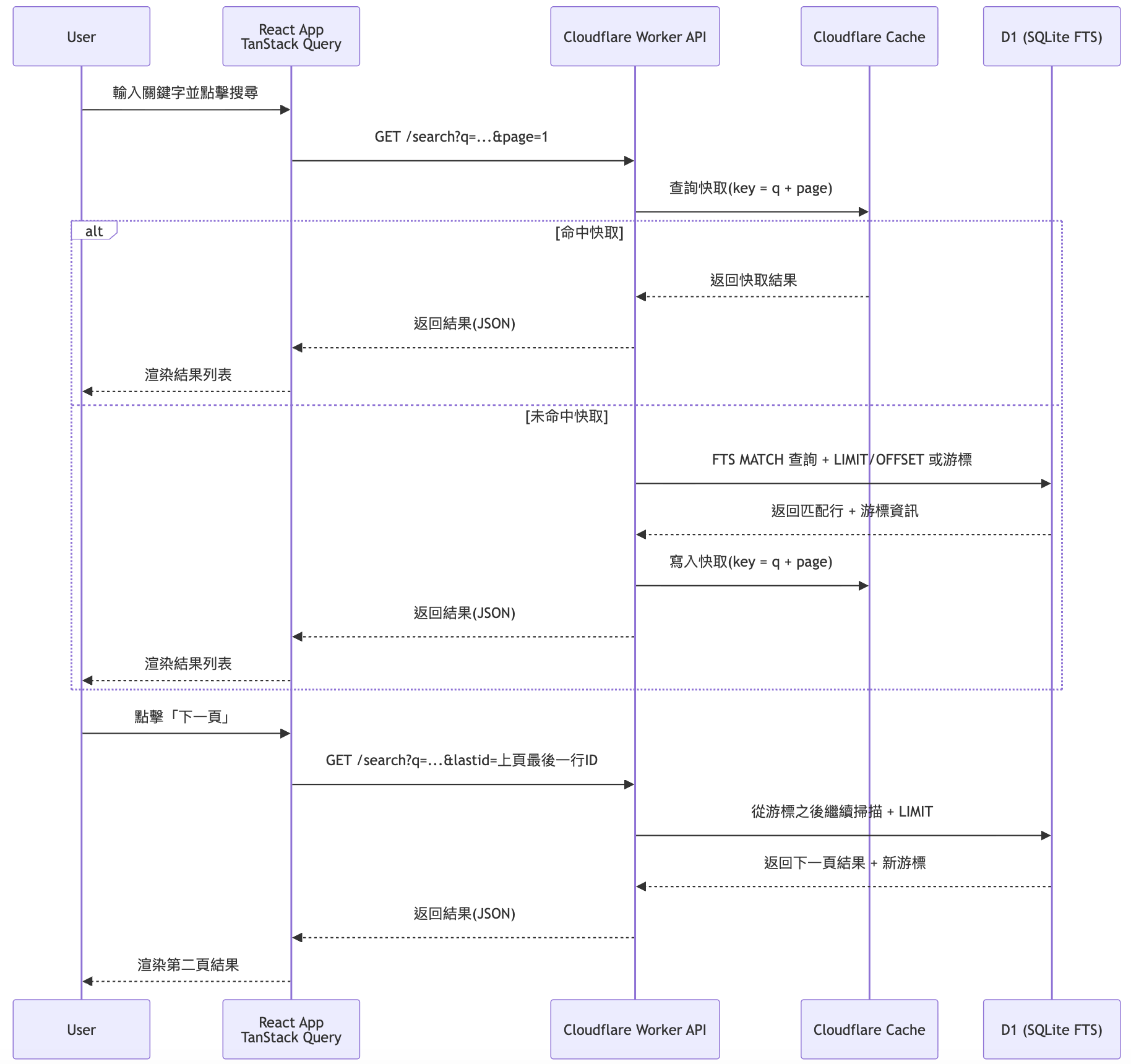
但是游標分頁是不能跳頁的,而我還是想要保留跳頁功能,於是又用了混合分頁的方式,如果用戶點擊上/下一頁則用游標分頁,點擊跳頁則用offset分頁。
而前端UI設計上則弱化跳頁選項的存在,盡量引導用戶用上/下一頁來瀏覽搜索結果,React Query的前端緩存功能也在這裡幫了很大的忙。
這個小Web App目前已大致完成,未來可能很快便能公開讓人使用。